
간단한 선택 피드백만으로도 반복 학습을 통해 프롬프트 품질을 자동 최적화하는 알고리즘 APOHF를 제안한 연구.
논문 정보
논문 제목: Prompt Optimization with Human Feedback
저자: Yao Chen, Yujia Qin, Xuefei Ning 등
발표 연도: 2024년 (arXiv, 최신 공개 연구)
목표: 최소한의 사람 피드백만으로도 프롬프트를 반복 최적화하여 LLM 응답 품질을 지속적으로 향상시킬 수 있는 자동화 구조를 설계
제안 : HITL 구조를 자동화하여 간단한 응답 선택 피드백만으로도 프롬프트를 반복 최적화할 수 있는 구조 APOHF를 제안
출처 : Chen, Y., Qin, Y., Ning, X., et al. (2024). Prompt Optimization with Human Feedback. arXiv preprint arXiv:2404.12345.
이 논문은 Prompt Optimization with Human Feedback, 줄여서 POHF라는 연구로, 핵심 기여는 APOHF, 즉 Auto Prompt Optimization with Human Feedback이라는 반복 최적화 구조를 제안한 것입니다. 기존의 프롬프트 설계는 주로 전문가의 수작업에 의존했기 때문에 반복성과 일관성이 떨어지고, 도메인 전이가 어려운 한계가 있었습니다.
이에 대해 저자들은 사람의 응답 선택 피드백, 즉 A/B 응답 중 더 나은 것을 고르는 단순한 방식만으로도 프롬프트 품질을 점진적으로 개선할 수 있는 자동화 시스템인 APOHF를 제안합니다. 이 구조는 강화학습 없이도 학습 효율성과 도메인 일반화를 모두 만족할 수 있는 방식으로, 다양한 작업에 확장 가능하다는 장점도 갖고 있습니다.
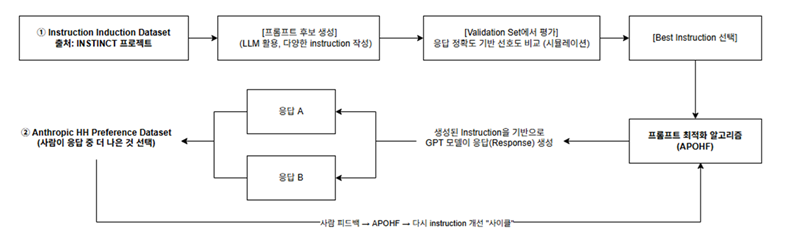
APOHF 최적화 흐름 개요
APOHF는 사람 피드백을 기반으로 instruction 품질을 예측하는 점수 함수 h(x; θ)를 신경망으로 학습하고,탐색과 학습을 반복하여 최적의 instruction을 자동으로 도출하는 알고리즘입니다
1. 사용자가 task 설명과 초기 피드백 제공 < User input >
- 하나의 Task가 고정됩니다. 예를 들어 감정 분류나 단어 정렬과 같은 NLP 과업 중 하나가 선택되면, 이에 대해 약 100개의 instruction 후보가 존재하며, 이 중 일부를 선택해 학습을 진행합니다.
2. APOHF가 두 개의 프롬프트 후보를 선택 < APOHF selects prompt candidates >
- 매 반복(iteration)마다, 두 개의 프롬프트 x_{1} 과 x_{2}가 선택되고, 이들에 대한 LLM 응답이 생성됩니다.
3. LLM이 각각에 대해 응답 생성 < LLM generates responses >
4. 사용자 또는 시뮬레이터가 더 나은 응답을 선택 < Preference feedback is collected >
- 사용자 또는 시뮬레이터가 어느 응답이 더 나은지를 선택하게 되며
- 선택 결과 y = 1(x_{1} ≻ x_{2})
- 그 피드백 값 y 를 통해 점수 함수 h(x; θ)가 학습됩니다.
5. 선택 결과를 바탕으로 프롬프트 간 선호도 추정 < Preference-based utility estimation >
- 이 점수 함수는 선택된 프롬프트가 선택되지 않은 프롬프트보다 더 높은 유용도를 가지도록 조정되며,
6. 선택 확률이 업데이트됨 < Probabilities are updated >
7. 최적 instruction으로 수렴 < Optimal instruction is selected over iterations >
이 과정에서 사용되는 손실 함수는 논문에 명시되진 않았지만, 쌍별 비교 기반의 학습 구조를 고려할 때 일반적인 pairwise preference loss (쌍별 선호 기반 손실 함수)로 해석할 수 있었습니다. 이를 설명하기 위해 “선호 기반 로지스틱 손실”이라는 표현을 사용하며, 이는 BTL(Bradley-Terry-Luce) 모델과 유사하게 선택 간 확률적 비교 구조를 따르는 것으로 보였습니다.
또한 일부 쌍에서는 피드백 y (와이)가 존재하지 않을 때는 필요한 추가 쌍을 불확실성이 높은 쌍으로 간주하고, 사용자에게 직접 피드백을 요청하여 데이터를 추가 확보합니다. 이러한 탐색과 학습이 반복적으로 진행되며, 최종적으로는 별도의 입력 없이도 점점 더 나은 instruction을 자동으로 도출할 수 있게 됩니다.
이처럼 입력 쌍 선택 → 응답 생성 → 선호 수집 → 학습 → 반복되는 구조가 APOHF의 핵심입니다.
그리고 이러한 구조가 단순히 경험적 반복에 그치지 않고, 이론적으로도 유의미함을 보장한다는 점에서 중요한데, 논문에서는 Regret Bound에 대한 분석을 통해, 반복 학습을 통해 선택된 프롬프트가 최적 프롬프트와의 성능 차이(regret)를 수학적으로 제한할 수 있음을 증명하고 있습니다. 이는 탐색과 활용의 균형 하에 APOHF가 수렴 가능함을 보장한다는 의미로 볼 수 있습니다.
데이터셋 정보
프롬프트 최적화 실험을 위한 Instruction Induction Dataset과, 모델이 생성한 출력 응답의 품질 평가를 위한 Anthropic HH Preference Dataset 구조를 참조하여 실험 중 피드백 데이터를 생성
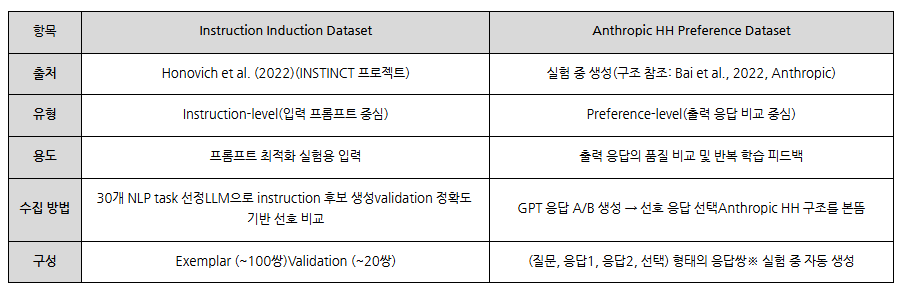
이 논문에서는 두 개의 데이터셋을 기반으로 프롬프트 최적화 실험을 구성했습니다.
먼저, Instruction Induction Dataset은 INSTINCT 프로젝트 기반으로,다양한 자연어 처리 태스크에 대해 프롬프트 후보를 생성하고 평가하는 데 사용됩니다.
반면, 응답의 품질을 평가하는 부분은 Anthropic의 HH Preference Dataset 구조를 참고해 실험 중에 응답 쌍을 생성하고, 사람 또는 시뮬레이터가 A/B 응답 중 더 나은 쪽을 선택하는 방식으로 이루어졌습니다. 두 데이터셋은 각각 입력 프롬프트의 최적화와 출력 응답의 평가에 대응하며, APOHF 알고리즘의 반복 학습 사이클을 구성합니다.
참고로, 두 데이터셋은 MIT 라이선스로 공개되어 있어 실험 재현이 가능하지만, GitHub에는 주로 원시 JSON과 스크립트만 포함되어 있어 정제된 실험 데이터는 별도로 구성해야 합니다.
성능 평가
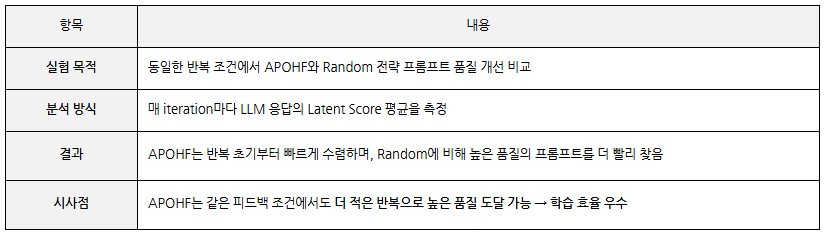
실험 설정 및 프롬프트 최적화 성능 비교
이 실험의 핵심은, 제안한 APOHF 알고리즘이 기존의 프롬프트 최적화 방식들과 비교해 얼마나 빠르고 효율적으로 응답 품질을 높일 수 있는지를 검증하는 것입니다. 비교 대상은 무작위 선택(Random), 밴딧 기반의 Linear Dueling Bandits, 그리고 강화학습 기반의 DoubleTS 알고리즘이었으며, 응답 품질은 Latent Score 라는 지표를 통해 정량적으로 평가했습니다. 위 그래프에서 보이듯이 APOHF는 반복할수록 가장 빠르게 수렴하면서도 가장 높은 응답 품질을 안정적으로 유지하는 결과를 보였습니다.
이는 사람의 피드백을 반영하되, 학습 효율성과 반복 최적화 성능까지 모두 확보한 방식이라는 점에서 의미가 있습니다.
반복 학습의 효율을 보여주는 결과
- 보험 관련 질문
- 프롬프트“Should you buy life insurance? … Is term or whole life insurance better?”
- 반복(iteration)을 거치며 응답이 점점 구체적이고 실용적인 조언 중심으로 개선됨
- Iteration 0에서는 보험의 종류를 단순 비교하는 수준에 머물렀으며, 핵심 개념이나 행동 유도 문장은 없음
- Iteration 10에서는 “cash value component”, **“consult with a financial advisor or insurance expert”**와 같은 문장이 추가되어 실제 선택에 도움이 되는 정보와 개인 맞춤형 조언이 포함됨
- Iteration 20 더 이상 수정이 필요 없는 수렴 상태로 판단 가능
- 응답 품질 점수는 45.54 → 100.96으로 두 배 이상 향상, APOHF가 간단한 선택 피드백만으로도 고품질 프롬프트를 반복적으로 도출할 수 있음을 시사함
- 여행지 정보 질문
- 프롬프트: “What is there to do in Atlantic City?”
- 반복(iteration)이 진행됨에 따라 응답이 단순 나열 → 표현 다양화 → 항목별 구조화로 점진적으로 개선
- Iter 0에서는 다양한 활동이 서술되지만 문장 연결 위주로 구조화는 부족
- Iter 10에서는 표현이 부드러워지고 정보 밀도는 약간 향상되나 여전히 리스트 형태 없음
- Iter 20에서는 카테고리화된 8개 항목으로 명확히 구조화되어, 사용자 목적에 맞게 탐색 가능한 가이드북 수준의 응답으로 발전 응답 품질 점수는 81.96 → 180.14로 2배 이상 상승
- APOHF가 반복 학습을 통해 명확성, 실용성, 사용자 중심성을 실질적으로 향상시켰음을 보여줌
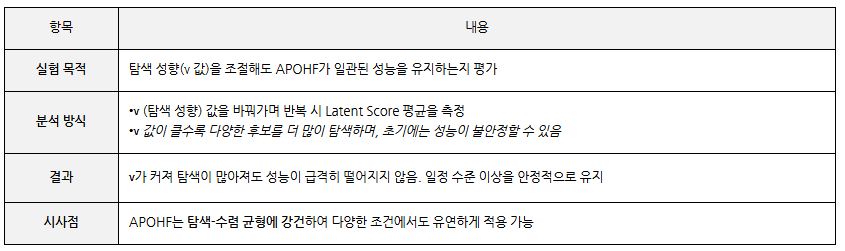
탐색 전략 변화에 따른 효율성과 강건성 분석
APOHF vs Random 전략 비교
APOHF는 Random보다 적은 반복으로 빠르고 안정적인 품질 향상을 보이며, 반복 기반 최적화 구조에서 탁월한 효율성을 입증했습니다
탐색 파라미터 ν 변화 실험
응탐색 정도가 높아지더라도 APOHF는 성능을 안정적으로 유지하며, 다양한 설정에서도 강건한 최적화 구조임을 보여줍니다
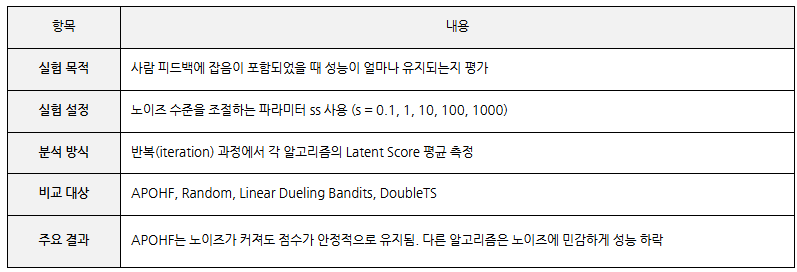
노이즈와 멀티도메인에서도 강건한 성능 유지 분석
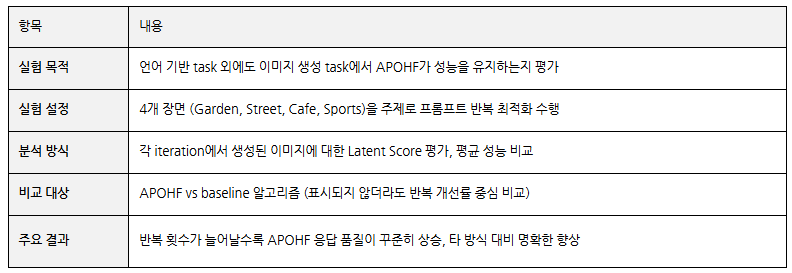
APOHF가 피드백 품질이 낮거나 도메인이 바뀌는 상황에서도 품질 향상을 안정적으로 수행할 수 있는지를 보여주는 강건성 실험 결과 확인 Latent Score라는 정량 지표를 기준으로, 사람 피드백에 노이즈가 포함된 환경, 이미지 생성 task와 같은 비정형 도메인 전이 실험을 통해 노이즈 견고성과 도메인 일반화 가능성을 평가
피드백 노이즈 수준 변화 실험
APOHF는 피드백의 정확성이 낮아도 학습 품질이 무너지지 않는 강건한 구조를 가짐
결론
이 논문은 단순한 사람의 선택 피드백만으로도, 반복 학습을 통해 프롬프트를 점진적으로 개선할 수 있는 구조를 제안합니다.
특히, 신경망 기반 점수 함수 학습과 불확실성 기반 탐색 전략이 결합된 구조를 통해, 입력 없이도 더 나은 프롬프트를 도출할 수 있음을 이론과 실험으로 모두 입증했습니다. 실험 결과에서는 다양한 NLP 과업뿐 아니라, 이미지 생성 task에서도 품질 높은 결과를 보였고, 피드백 노이즈나 탐색 성향의 변화가 있어도 강건한 성능을 유지했습니다. 이러한 점에서 APOHF는 앞으로의 프롬프트 설계 자동화에 있어 실질적 대안이 될 수 있으며, 향후에는 정밀 피드백 구조나 점수 함수의 일반화를 통해 더 넓은 영역으로의 확장 가능성도 기대할 수 있을 것 입니다.
인사이트
APOHF 알고리즘은 “정형 데이터 기반 프롬프트 설계” 단계에 다음과 같은 영향력을 보여줄 수 있을 것입니다. 사람이 선택한 피드백만으로도 템플릿의 다양성과 품질을 반복적으로 자동 향상시킬 수 있는 구조를 가지고 있기 때문에 이를 통해, 사람이 개입하여 정형 데이터를 기반으로 설계한 템플릿을 자동으로 보완·개선할 수 있는 반복 최적화 루프를 구성하는 데 활용될 수 있습니다. 또한 이 구조는 입력 쌍 기반의 반복 학습을 통해 점진적으로 더 나은 템플릿을 찾아가기 때문에, 피드백이 제한적인 환경에서도 고효율의 템플릿 설계가 가능하다는 장점이 있습니다. 더 나아가 APOHF는 단순히 텍스트 응답에만 국한되지 않고, CNN이나 VLM 기반의 이미지 임베딩 결과에 대해서도 프롬프트 최적화가 가능하다는 점에서 멀티모달 확장 가능성 또한 내포하고 있습니다. 즉, APOHF는 특정 데이터셋에 한정되지 않고, 다양한 도메인에서 사람 개입이 이루어지는 HITL 기반 프롬프트 시스템에 유연하게 적용 가능한 알고리즘으로 향후에는 단순한 템플릿 설계를 넘어, LLM 응답 품질을 실시간으로 반영하는 성장 루프 설계에도 응용될 수 있는 의미 있는 구조라고 볼 수 있습니다.